“Multiple” special character replacements in “Multiple” columns
Modularization and Iteration in M Query

Drawing parallels between data wrangling in Python Pandas and M query ,when a client is not open to a Python solution, has been an ongoing obsession. Here is a real-world scenario recently implemented for a client who has signed contracts in PDF format that offers incentives for sales. The task is to bring the data into the model and the data cleaning involves removing trademark symbols from product names from the PDF data.
Note: The data used in the article is a toy dataset with select subset of features from the original PDF, that are pertinent to this article.
Understanding our data and the goal
You can find the input file and solution here.
If working your way to the solution, start with new Power BI file and using the GUI, read the provided PDF using Get Data->PDF. Rename the query to Read Contract PDF.


As seen above, it is likely that Power Query performed an important step in data cleaning for you: setting data types. But as of now we do not want that to execute and so delete that step. We will handle it later.


The quick glance at the data will inform you that it is sprinkled with trademark symbols and images that need to be cleaned up before we can store it in our model.
The simplest form of cleaning is something you can perform through the GUI or by entering the formula in the formula bar. The fire image in Product, that was translated to the string “[image]”, for instance, can be removed with Text.Replace in one go. You will also notice that this very product appears with an emoji 🔥 in another column.
In the GUI

OR
Insert into formula bar
Click on the fx symbol to insert a new step and enter the below.
=Table.ReplaceValue(#"ChangedType",
"[image]",
"",
Replacer.ReplaceText,{“Product Name”})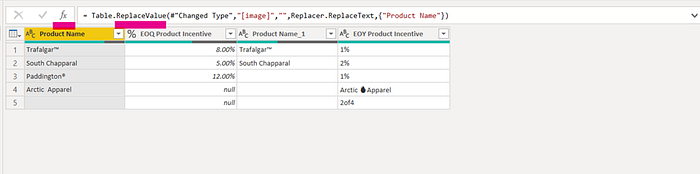
Our Goal : Clean up the emojis and special characters
Creating the function to replace special characters and emojis
Under New Source, select Blank Query to create Query1. Let’s be really obvious and name this Query1 to : Function to replace special characters.
Then with the function selected, click on Advanced Editor.
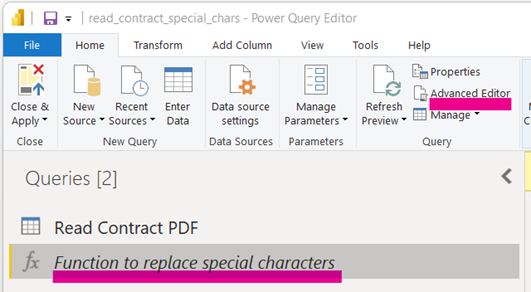
Type in the following code. Yes, you will have to take a leap of faith in placing this in. But I will explain why it works, in a bit, at length!
Step A : Create the function with ONE parameter
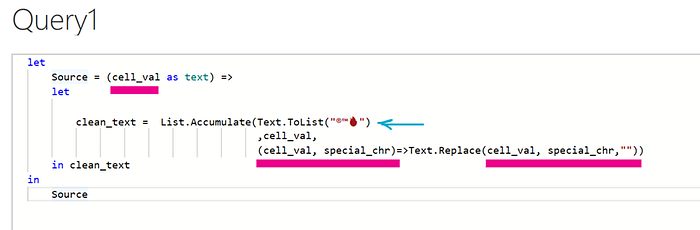
Code:
let
Source = (cell_val as text) =>
let
clean_text = List.Accumulate(
Text.ToList(“®™🔥”)
,cell_val,
(cell_val,special_chr)=>
Text.Replace(cell_val, special_chr,””)
)
in
clean_text
in
SourceGive it a name:

Each value of the cell that the function will act on will be sent in as an argument to the parameter of the function as cell_val.
I simply Ctrl+C’d and Ctrl+V’d, that is, copied and pasted, each of the emojis and trademarks from the contract PDFs, into the string.
NOTE: Any and all items in the string will be scrubbed from the cell value and so use caution in placing commas and spaces in that string. If they are in the string, all occurrences if commas and spaces will be removed .
Start List.Accumulate Detour
Notice that in the function we created, List.Accumulate features prominently. What does this workhorse of a function do?
We will keep the “Accumulate” intention of function in our mind. It will help us understand the arguments to be passed to the function.
Note :Skip the broader discussions below and return to it if you want to learn about List.Accumulate in a manner that can be applied to other scenarios
PARAMETER 1: The list
Our list here is the list of special characters in the PDFs. We create a list of them by first setting up a string of all of the possible special characters we might encounter in the PDF and then separate them into List elements by passing them through Text.ToList
Broader discussion on PARAMETER 1: The list argument in List.Accumulate, in fact, can be a list of characters, numbers, records, rows in a table….in other words, the elements can be of any type in the list provided as the first argument. This is truly what makes List.Accumulate such a powerful method. It provides the all-important iteration (FOR loop) over a variety of object types. The accumulation occurs over this list.
PARAMETER 2 : The seed : It is the column text to be scrubbed.
Broader discussion on PARAMETER 2: The seed is an initial value to be provided for the accumulation. You can specify it to be null, that is, “no particular value” to have the function ignore it, but it is not “optional”. Say you want the accumulation to start with a base value of 1000, then the initial state of the accumulation will be set to a 1000 with this seed.
PARAMETER 3 The implementer of the accumulation is a function with no name! It is sent two arguments, the state (the cell text) and the current value which is the special character in the current element of the list in each pass of the iteration. We will pass these two arguments to Text.Replace to replace any occurrence of the special character in the cell text with an empty string “”.
Arguments to the Lambda function
a. State : text in the cell value passed in.
b. Current : each special character from the list of special characters that Text.ToList created.
The function we use to work on the state and current available to us is the Text.Replace function. Text.Replace now takes the text of the column value sent in as state and replaces the current special character with an “” (empty string) and stores the result back into state. This last bit is important to note since after every iteration through the list of special characters, we want to preserve the removal of the last one from the cell text and act upon this new state, as we scrub the current special character off the text.
Broader discussion on PARAMETER 3: The case of the disappearing function name
We have another function within ListAccumulate, only this time, this function does not have a name. It is “Anonymous” in that sense. Also called lambda functions, they are really handy, since they do not have to be “set up” beforehand. We can just specify the parameters in parenthesis in the place where we want to call the function and use them “in situ”. The syntax definition of the function requires that the symbol => follow the parameters in parenthesis and that is followed by the action to be applied on the arguments.
Broader discussion on replacement strategy
a. To keep it straight, we start off with a list of objects to iterate over and to “accumulate” to a state.
b. This list is passed to the List.Accumulate function as the first parameter.
c. List.Accumulate starts off with a “state” (as in, the accumulation value so far). We set the initial state with the seed.
d. Now as the List.Accumulate loops or iterates over the list, it also has available to it the “current” object or element in addition to the state.
e. It sends both the accumulation state thus far in the iteration as well as the “current” element to another function. Only, this function which will be the accumulation strategy, has no name. It is generally what is known as the “lambda function”.
f. So, imagine calling a function with an invisible name, then specifying the arguments as in (state, current). The syntax of the function then expects a => symbol that points to what will occur next with the state and current value.
g. What happens next is that the function you specify will work on the current element and state in some manner you specify, and update the “state”.Still confused as to how List.Accumulate aids us in our current scenario? We, after all, have nothing to total or aggregate or concatenate (typical aggregation method of characters or string), do we? We are only looking to scrub special characters off the text in the table’s columns.
Here’s how: List.Accumulate provides us with the elusive iterative “FOR LOOP” we might go scrounging for when setting off with M Query.
TESTING THE FUNCTION VISUALLY
It helps testing the function out before applying it to the columns in the table.
- Here is our string of special characters “ ®™🔥”
At every iteration, the current value is an element of the list, that is we will remove the current special character.
= Text.ToList(“®™🔥”)
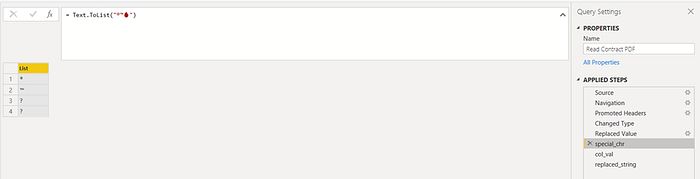
2. So if the below is our cell text:
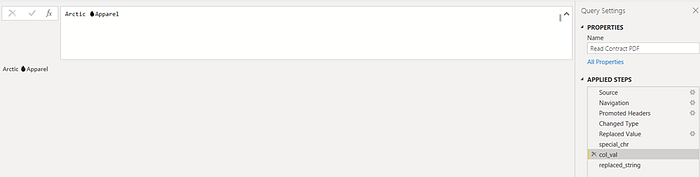
3. The initial state is the cell text and as each special characters becomes the current value, the state of the accumulator is updated with the cell text with current special character replaced with empty string.
4. And so for the cell text seen above we end up with:
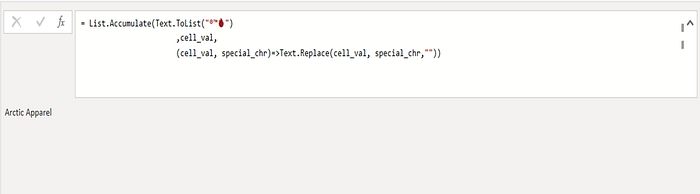
End List.Accumulate Detour
Continuing on with the “Read Contract PDF” query
Now that we have a function that does the “dirty” work of cleaning up text, we will apply it to every column in the query “Read Contract PDF”.
Step 1 : We make a list of columns Table.ColumnNames Entering the next step in the formula bar:

NOTE: You can also work directly in the Advanced Editor. I just find working in the Advanced Editor easier, as I can type in the step names in the format I want. I know that it is best practice to have spaces and common language words text as step names but the “#” and the quotation marks “” surrounding the names are rather distracting!
Step 2: Prep for the function call be removing all nulls from the cell texts that we will pass to the function.
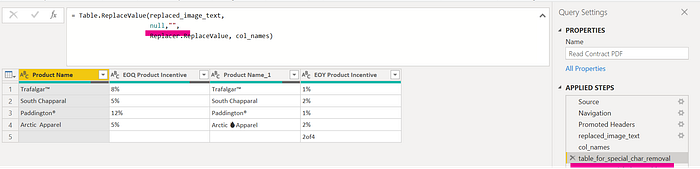
Step 3: With the column names and function to transform in hand, our task is amazingly simplified by the function TransformColumns.
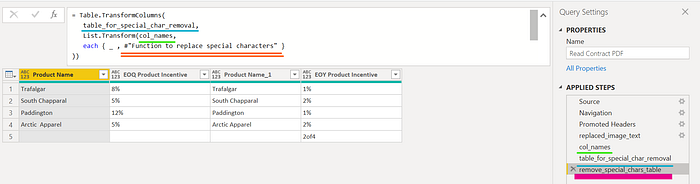
NOTE: Skypoint Cloud’s Brian Grant’s blog and video on this topic can be found here for a comprehensive look at this function.
Start Table.TransformColumns Detour
Here’s how the Table.TransformColumns function works.
PARAMETER 1 : The table.
As with all Table functions, Table.TransformColumns expects a table as its first argument, which in our case is the name of the last step, by which time we have prepped the data by removing the image string and setting nulls to empty strings.
PARAMETER 2: The list of columns to transform.
As the name of the function indicates, this is the list of columns we want to transform and so we send in the col_names list we created earlier.
PARAMETER 3: For each column specify a LIST of
a) column name and b) the function that transforms the column.
Here is where our modularization pays off. By creating a function that replaces special characters and that we tested earlier, we can now use it over all the columns uniformly. If we need to add another special character we spot in a new PDF contract, we just add to the string in this function, in one common function query, and it will clean that character from all the columns! That’s efficiency for you.
Broader discussion on Table.TransformColumns
This powerful function also helps us apply a function over multiple columns in one succinct piece of code and improves code readability and thus maintainability.
End Table.TransformColumns Detour
NOTE: Check out this syntax in the documentation.
Final Step
Now that we have concluded the clean up, we can set the final data types in all columns for further processing. The page number is troublesome isn’t it? That has been left as a challenge for you to try out next…

EXERCISE
And now it is your turn. You must have undoubtedly spotted the page number in the last column” “2of4” Work out as an exercise, the removal of this page number. Ask yourself, can you get away without adding additional columns. Can you create a common function to clean all page numbers? Can you use List.Accumulate to remove the numbers?
Also look into Text.Replace with a list {“0”..”9”}…What have been your data cleaning challenges and how did you resolve those? Let me know….
